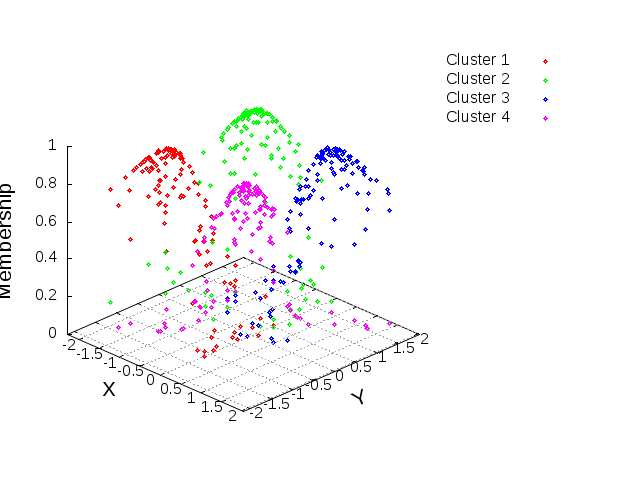
Data Clustering - Clustering two-dimensional (2D) data
Introduction In this post, we will show a simple example of clustering data in two dimensions. As usual, we will try to keep terminology and ideas as simple as possible.
Data clustering is the partitioning of data into a number of clusters such that all data within a given cluster are similar to each other and dissimilar to data in other clusters. A metric is normally used as the criterion for data clustering and one of the most popular is the distance metric, where data within a cluster are closer to each other and further from data in other clusters.